Erika Updates #0: A Publishing Experiment
Look behind the curtain of a PhD project

A (fun!) publishing experiment
During grad school I had a habit I called “Erika Updates.” Every few weeks, I would send out a brief PDF describing experiments I had done recently to the Erika-Updates email list. When I challenged myself to explain my science to other people in plain english, I found that I was better able to interpret data and decide what to try next. I came to really enjoy writing Erika-Updates. I relied on them to form the narrative backbone of my science. Over the course of my PhD (in Biological Engineering, from MIT), the Erika-Updates email list accumulated members — often friends in other labs, or folks I met at conferences. They gave me invaluable, immediate feedback at the moment it mattered: when my science was hot-out-of-the-oven and still in play. A lot of the people who were on Erika-Updates are now long-term collaborators, colleagues, and friends.
Now that I’ve started my own lab, I find myself often referencing my old Erika-Updates and sending them to lab members. I invariably get the response: “Wow!” “This is so cool!” “Why doesn’t everyone do this!?” I’ve decided to do an experiment where I release Erika-Updates publicly. There are 52 updates, and I’ll post them once a week, accompanied by some commentary in a substack post. I hope that doing this can give my own lab members a chance to peek behind the curtain at the development process of techniques they use today, show incoming students the narrative arc of a bioengineering project, and perhaps also de-mystify what the routine of a research scientist looks like for non-scientists.
There’s a fourth readership I’d love to reach: people trying to reform publishing. Here’s your case study! There are enormous differences between Erika-Updates and the peer-reviewed papers (Paper #1, Paper #2, and Paper #3) that I later published on the same material. They differ in time scale (immediate versus delayed by multiple years of writing, academic politics, and peer-review), production value (perfectly serviceable versus a work of scientific illustration in itself), readability (fun to read versus dense and stuffy), and narrative (short experiment-focused episodes versus a grandiose whole-season plot line). Notably they don’t tend to differ very much in content or conclusions, with a few exceptions I’ll highlight. In many ways Erika-Updates are better than traditional papers at communicating science. What we lack is a publishing ecosystem that is capable of distributing this sort of content in a way that fits into the competitive, political, and prestige-based academic system. For folks with ideas for reforming publishing, tackle this thought experiment: in your vision of publishing in the future, how would this material be published, how is credit handled, and what are the consequences for competition? I would love to identify a better publishing practice that I can use today with my lab.
Background on the science
Before diving into the first Erika-update, let me give you a brief snapshot of the project. There’s also short videos explaining the premise of this project at a basic level (end at 6:50), or at a slightly more advanced level (end at 12:25).
All life on Earth uses the genetic code to write down instructions for building organisms from the molecular level up. The genetic code is surprisingly simple, at least chemically. The 20 amino acids in the genetic code are all relatively tame, and occupy only a tiny fraction of possible chemical space. Scientists have been interested in expanding the genetic code to include more chemically diverse amino acids. From a scientific standpoint, genetic code expansion helps us understand the origins and limits of life as we know it. From an engineering standpoint, more sophisticated chemical building blocks have the potential to let us engineer better proteins, including therapeutics, biomaterials, enzymes, and the list goes on!
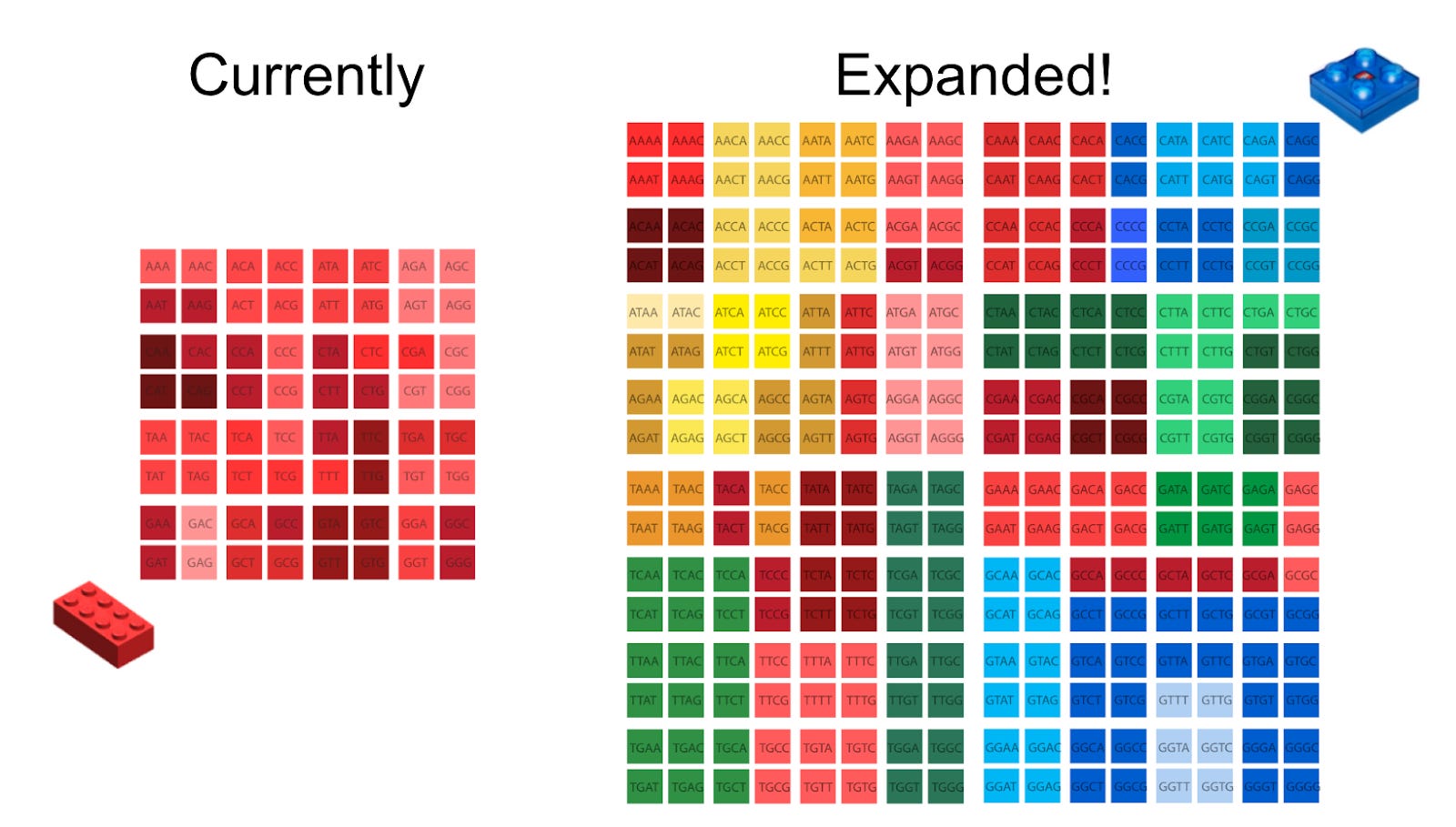
I wanted to investigate a new type of genetic code expansion: expanding the entire genetic code from “three base codons” to “four base codons”, thus taking us from a theoretical maximum of 64 different amino acids to a maximum of 256 amino acids. This is sort of like the transition consumer electronics went through in the early 2000s from 32-bit computers to 64-bit computers: reengineering the hardware to make the ‘names’ the operating system uses longer allows you to increase the capabilities of the system enormously.
What’s involved in making the genetic code 4x bigger? Today, the genetic code is ‘written down’ inside of living organisms in their tRNAs and AARSs, which are two types of biomolecules that work together to define how genes are converted into functional proteins. I might need to engineer one or both of these types of molecules to alter the genetic code!
A bit more about our key players:
tRNAs. “Transfer RNAs” are t-shaped adaptor biomolecules: they convert a codon into an amino acid. They do this by having an anticodon at the bottom that physically matches the codon like a lock and key, and they carry with them the correct amino acid at the top. The ribosome is a machine that is designed to use these little adaptor biomolecules to convert instructions written in DNA into strings of amino acids that can fold up into proteins
AARSs. How did the tRNA get the amino acid at the top? “Aminoacyl tRNA synthetases”, or AARSs, are biomolecules responsible for attaching the correct amino acid onto the top of each tRNA. (And yes, they’re also a tongue twister!)

To tackle this project, I knew I might need to engineer quite a few different components in bacteria, including tRNAs and AARSs, which are the two types of biomolecules that determine the genetic code, and perhaps even the ribosome itself. I ended up focusing mostly on engineering tRNAs that decode four-base codons by simply making the anticodon at the bottom one base bigger. Early on in the project, these are called “frameshift tRNAs” or “frameshift suppressors”, and later on I started referring to them as “quadruplet tRNAs” or qtRNAs for short.
Themes to look for
Along the way there were a few little sub-plots to look out for:
Surprise! It’s toxic. If you reach all the way down into the operating system of a microbe and start messing with things, naturally, sometimes it’s bad news for the microbe. It took a long time for me to figure out how to adapt standard lab techniques to accommodate engineering toxic components.
Winding up to evolution. A big goal of this project was to use a really big hammer (called PACE) to do engineering really rapidly. PACE is such a big hammer that you need to use a lot of little hammers first to make sure you’re ready.
Gotta catch ‘em all. If this is going to work, it needs to work for all 20 canonical amino acids. Most people who do a PhD these days aim to engineer just one biomolecule, so aiming for 20 was a challenge in itself
Tooling Up. Remember how I said PACE is a big hammer? And how I said that I wanted to do 20x more work than people usually do in a PhD? To solve this problem, I had to invent an upgraded hammer that was like a… impact driver. It’s called “PRANCE.” Don’t worry I’ll tell you all about it and it worked great.
No qtRNA left behind. If you want to make 20 things, and you have 18 working but the last two suck, then even though you really don’t want to, you need to actually try to make the last two work, and it is hard going!
Outsmarted by a billion year old protein. At the very end of my PhD, I had a smart idea that didn’t end up working at all, and I ended up feeling rather silly. It was the most classic science outcome and I could not be more happy with my last experiment of grad school than to have been so thoroughly outsmarted by Nature - again.
Want more?
I had a lot of fun with this project during my PhD, and I hope that this publishing experiment will be a fun read! If you want to follow along, you can get updates approximately weekly by signing up through substack below. I’ll also post on linkedin and twitter.
If you’re curious about more background on the project, Quanta/Wired wrote an excellent article on it, and I also talked a lot about this project as a guest on the molpigs podcast.
Thanks to Anjali Chadha, Lada Nuzhna, Ben Thuronyi, Maxime Crabé, and Ollie Hayes for early feedback on this project. If you have ideas for what I should cover in the blog post, suggestions for vocabulary to define, questions about the science, or other comments, please do reach out by twitter DM - I’d love to hear from you!
Hello Dr Erika,
Looking forward for the series.
Fun fact, somehow I found your writing on twitter page then when I read, I found my pal: tRNA and Aars (when I did my master degree). Hence, can’t wait for your upcoming stories!
Best,
Aditya
I'm really looking forward to this series, I unfortunately didn't get that much lab research experience in my college experience, so this is exciting!